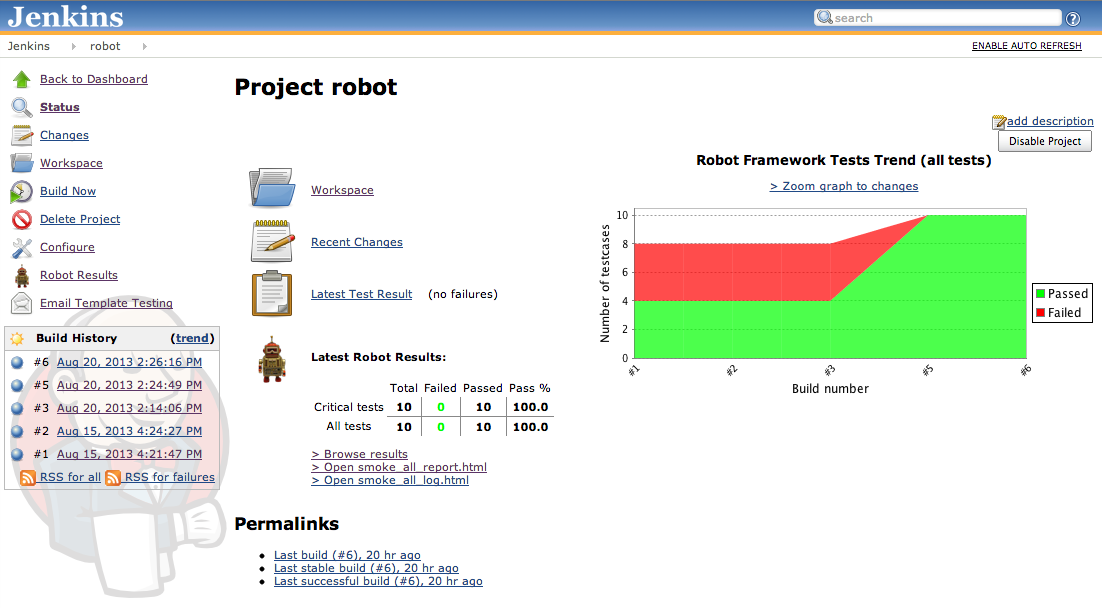
In a previous post, I discussed solving intermittent issues aka building more robust automated tests. A solution I did not mention is the simple “just give it another chance”. When you have big and long suites of automated tests (quite classic to have suites in the 1000’s and lasting hours when doing functional tests), then you might get a couple of tests randomly failing for unknown reasons. Why not just launching only those failed tests again? If they fail once more, you are hitting a real problem. If they succeed, you might have hit an intermittent problem and you might decide to just ignore it.
Re-executing failed tests (–rerunfailed) appeared in Robot Framework 2.8. And since version 2.8.4 a new option (–merge) was added to rebot to merge output from different runs. Like explained in the User Guide, those 2 options make a lot of sense when used together:
# first execute all tests
pybot --output original.xml tests
# then re-execute failing
pybot --rerunfailed original.xml --output rerun.xml tests
# finally merge results
rebot --merge original.xml rerun.xml
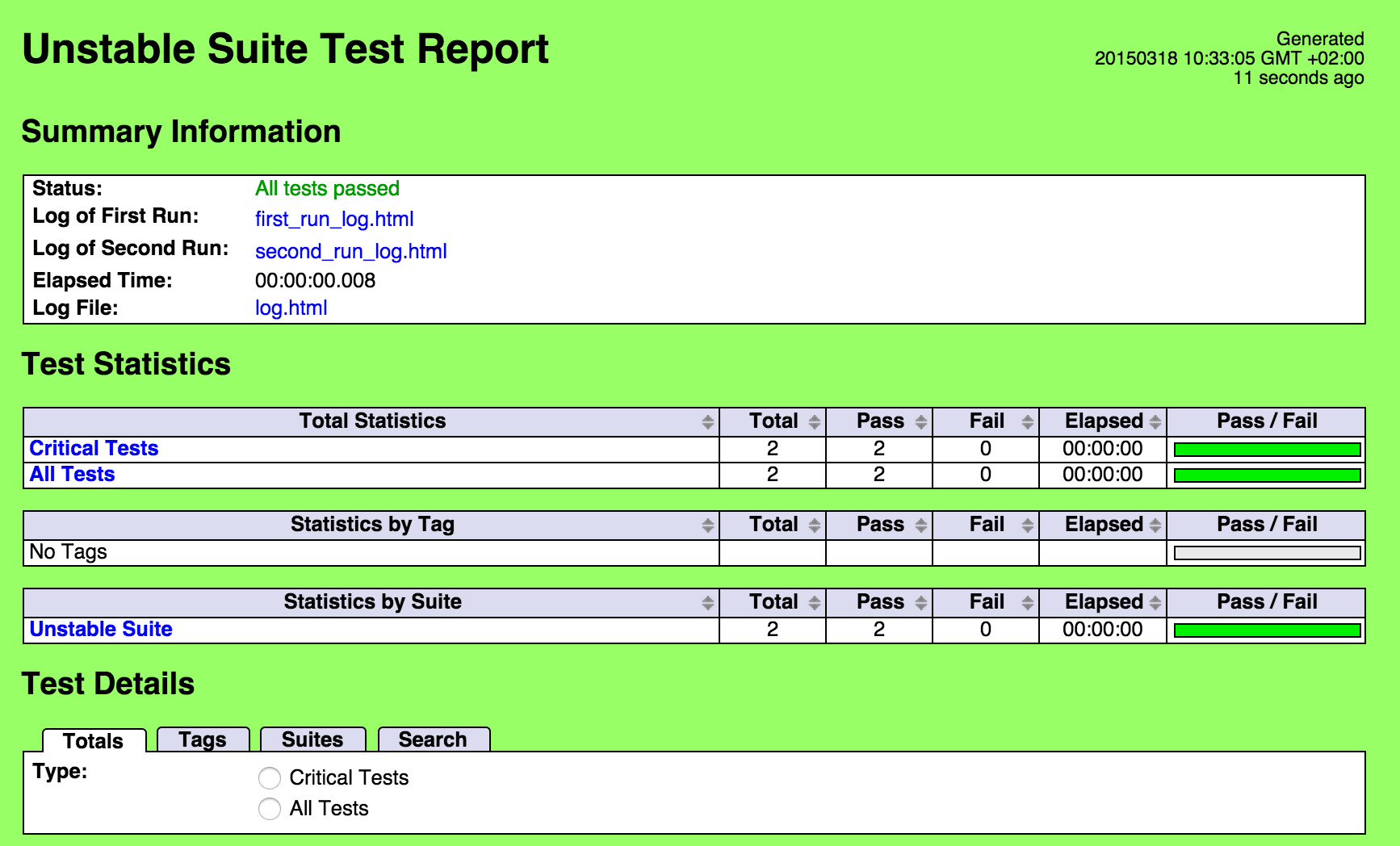
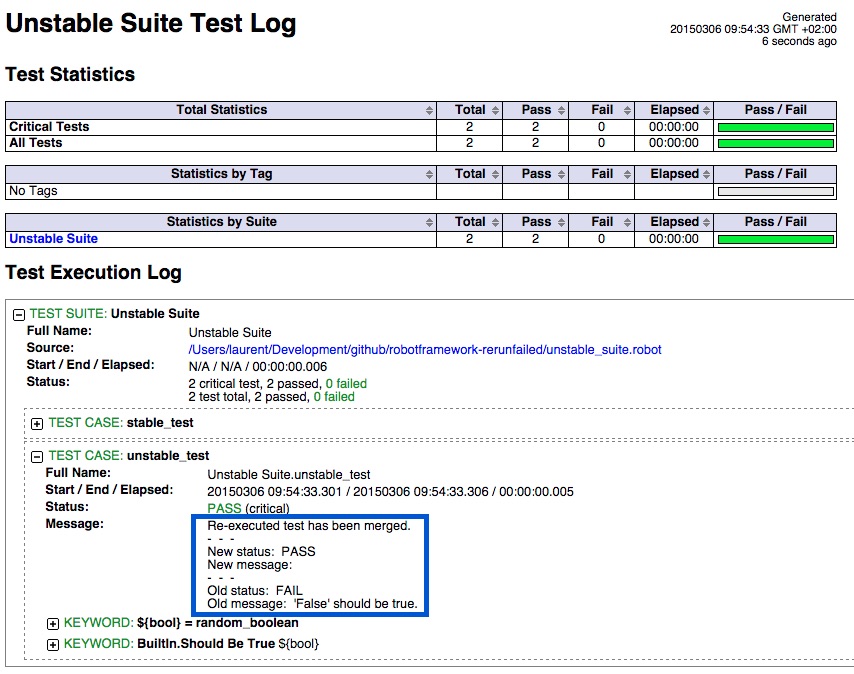
This will produce a single report where the second execution of the failed test is replacing the first execution. So every test appears once and for those executed twice, we see the first and second execution message:
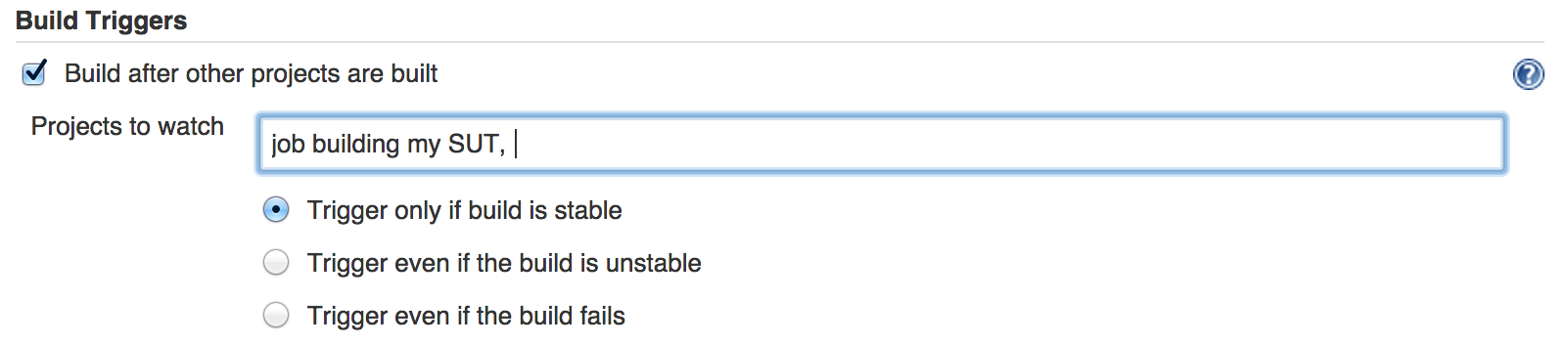
Here, I propose to go a little bit further and show how to use –rerunfailed and –merge while:
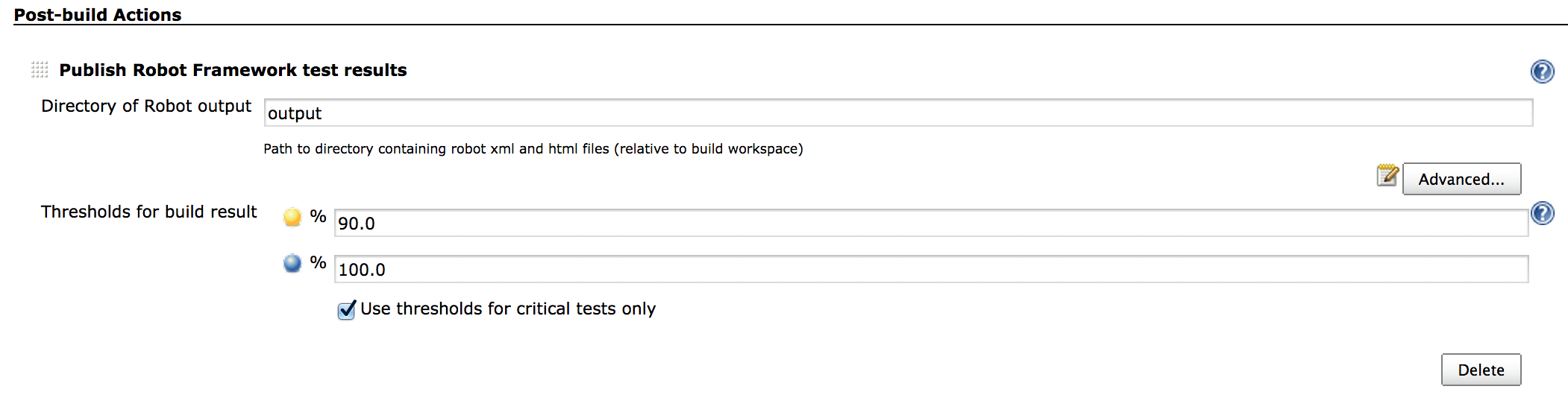
- writing output files in an “output” folder instead of the execution one (use of –outputdir). This is quite a common practice to have the output files written in a custom folder but it makes the whole pybot call syntax a bit more complex.
- giving access to log files from first and second executions via links displayed in the report (use of Metadata). Sometimes having the “new status” and “old status” (like in previous screenshot) is not enough and we want to have details on what went wrong in the execution, and having only the merged report is not enough.
To show this let’s use a simple unstable test:
*** Settings ***
Library String
*** Test Cases ***
stable_test
should be true ${True}
unstable_test
${bool} = random_boolean
should be true ${bool}
*** Keywords ***
random_boolean
${nb_string} = generate random string 1 [NUMBERS]
${nb_int} = convert to integer ${nb_string}
Run keyword and return evaluate (${nb_int} % 2) == 0
The unstable_test will fail 50% of times and the stable test will always succeed.
And so, here is the script I propose to launch the suite:
# clean previous output files
rm -f output/output.xml
rm -f output/rerun.xml
rm -f output/first_run_log.html
rm -f output/second_run_log.html
echo
echo "#######################################"
echo "# Running portfolio a first time #"
echo "#######################################"
echo
pybot --outputdir output $@
# we stop the script here if all the tests were OK
if [ $? -eq 0 ]; then
echo "we don't run the tests again as everything was OK on first try"
exit 0
fi
# otherwise we go for another round with the failing tests
# we keep a copy of the first log file
cp output/log.html output/first_run_log.html
# we launch the tests that failed
echo
echo "#######################################"
echo "# Running again the tests that failed #"
echo "#######################################"
echo
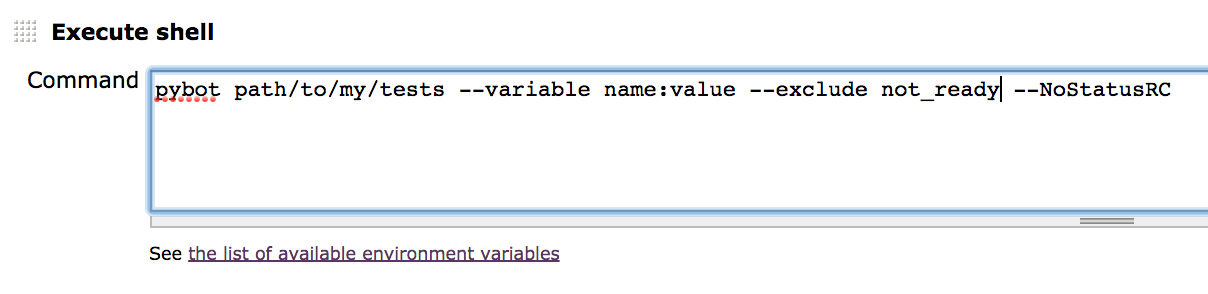
pybot --outputdir output --nostatusrc --rerunfailed output/output.xml --output rerun.xml $@
# Robot Framework generates file rerun.xml
# we keep a copy of the second log file
cp output/log.html output/second_run_log.html
# Merging output files
echo
echo "########################"
echo "# Merging output files #"
echo "########################"
echo
rebot --nostatusrc --outputdir output --output output.xml --merge output/output.xml output/rerun.xml
# Robot Framework generates a new output.xml
and here is an example of execution (case where unstable test fails once and then succeeds):
$ ./launch_test_and_rerun.sh unstable_suite.robot
#######################################
# Running portfolio a first time #
#######################################
==========================================================
Unstable Suite
==========================================================
stable_test | PASS |
----------------------------------------------------------
unstable_test | FAIL |
'False' should be true.
----------------------------------------------------------
Unstable Suite | FAIL |
2 critical tests, 1 passed, 1 failed
2 tests total, 1 passed, 1 failed
==========================================================
Output: path/to/output/output.xml
Log: path/to/output/log.html
Report: path/to/output/report.html
#######################################
# Running again the tests that failed #
#######################################
==========================================================
Unstable Suite
==========================================================
unstable_test | PASS |
----------------------------------------------------------
Unstable Suite | PASS |
1 critical test, 1 passed, 0 failed
1 test total, 1 passed, 0 failed
==========================================================
Output: path/to/output/rerun.xml
Log: path/to/output/log.html
Report: path/to/output/report.html
########################
# Merging output files #
########################
Output: path/to/output/output.xml
Log: path/to/output/log.html
Report: path/to/output/report.html
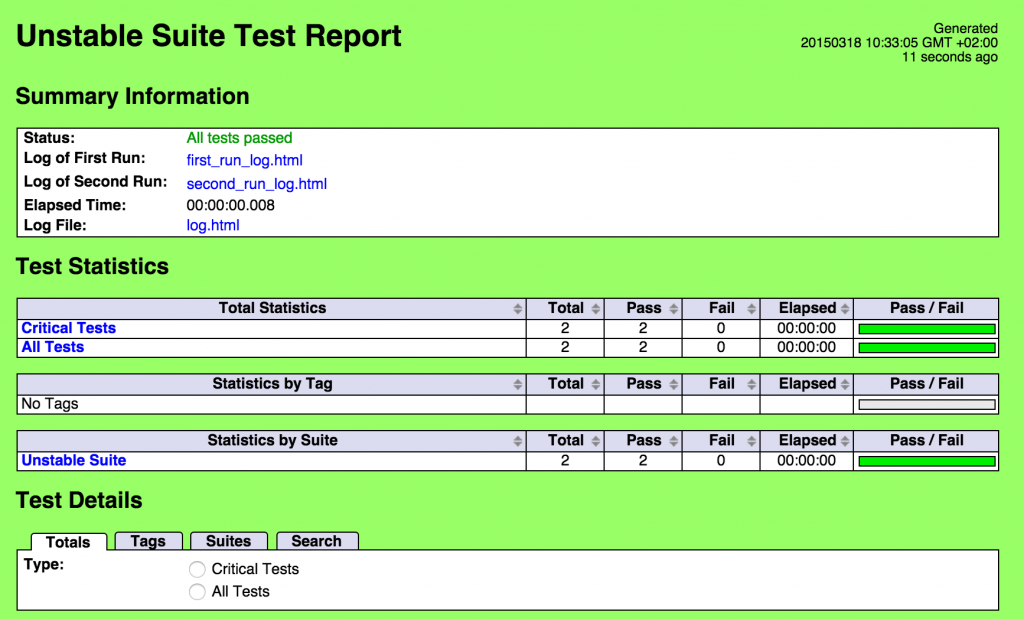
So, the first part is done: we have a script that launch the suite twice if needed and put all the output in “output” folder. Now let’s update the “settings” section of our test to include links to first and second run logs:
*** Settings ***
Library String
Metadata Log of First Run [first_run_log.html|first_run_log.html]
Metadata Log of Second Run [second_run_log.html|second_run_log.html]
If we launch our script again, we will get a report with links to first and second run in the “summary information” section:
The script and the test can be found in a GitHub repository. Feel free to comment on that topic if you found out more tips on those Robot options.