Vous entendez parler des podcasts mais n’avez pas réussi à comprendre comment en écouter avec votre iPhone ? Nous allons détailler ici chaque étape afin que même les plus débutants d’entre vous puissent y arriver. Nous utiliserons l’application “podcast” d’Apple.
1) trouver l’application podcast
L’application “Podcast” est livré par défaut avec vote iPhone. Et comme il est impossible de la supprimer, elle doit encore être là. Si vous ne la trouvez pas, le plus simple est de faire une recherche. Pour ça, faites un balayage vers la droite sur l’écran d’accueil de votre iPhone, et vous arrivez dans la page de recherche où vous pouvez chercher “podcast”:

2) Lancer l’application Podcast
Au premier lancement de l’application, vous arrivez dans l’onglet “non lus” (la barre d’onglet est en bas de l’écran). Comme l’indique l’application, vous n’avez pas de podcast pour l’instant et il va falloir aller en choisir.
3) sélectionner un podcast
Sur l’écran d’accueil de l’application podcast, vous pouvez cliquer sur “Afficher les podcasts recommandés”. Au moment de l’écriture de cet article, la liste proposée était la suivante:
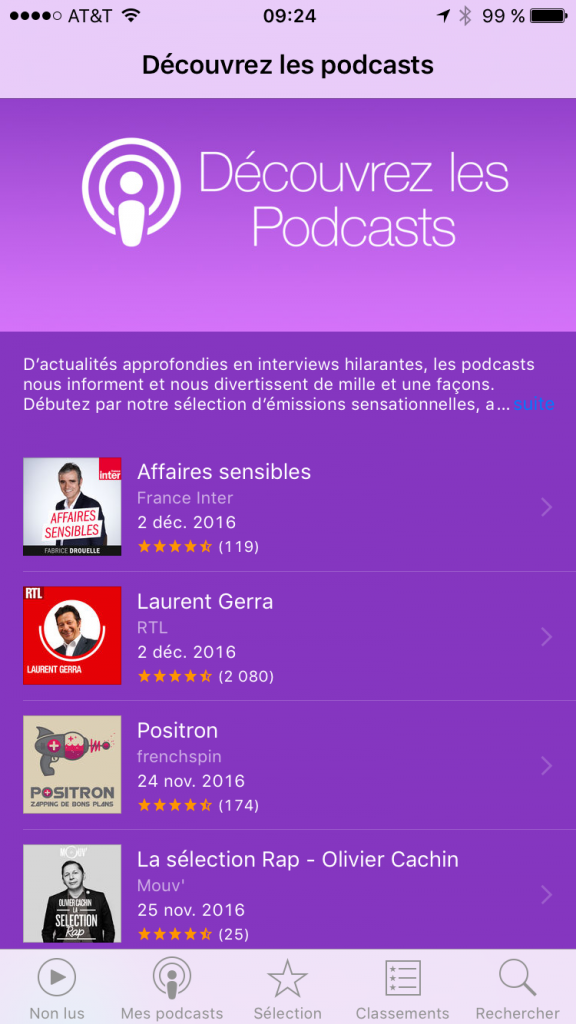
Avant de choisir un podcast dans cette liste, vous pouvez aussi cliquer dans les onglets “Sélection” et “Classements” afin d’avoir un plus grand choix de podcasts.
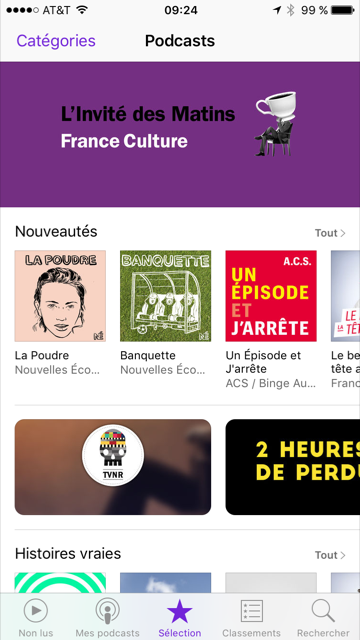
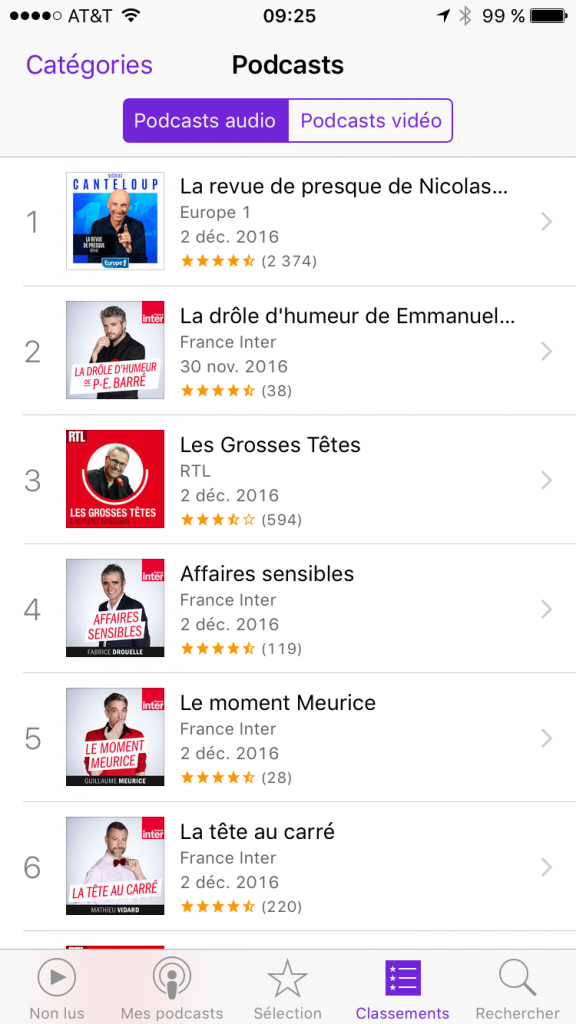 Dans l’onglet “Classements”, vous pouvez cliquer sur “Catégories” afin de filtrer la liste sur une seule catégorie.
Dans l’onglet “Classements”, vous pouvez cliquer sur “Catégories” afin de filtrer la liste sur une seule catégorie.
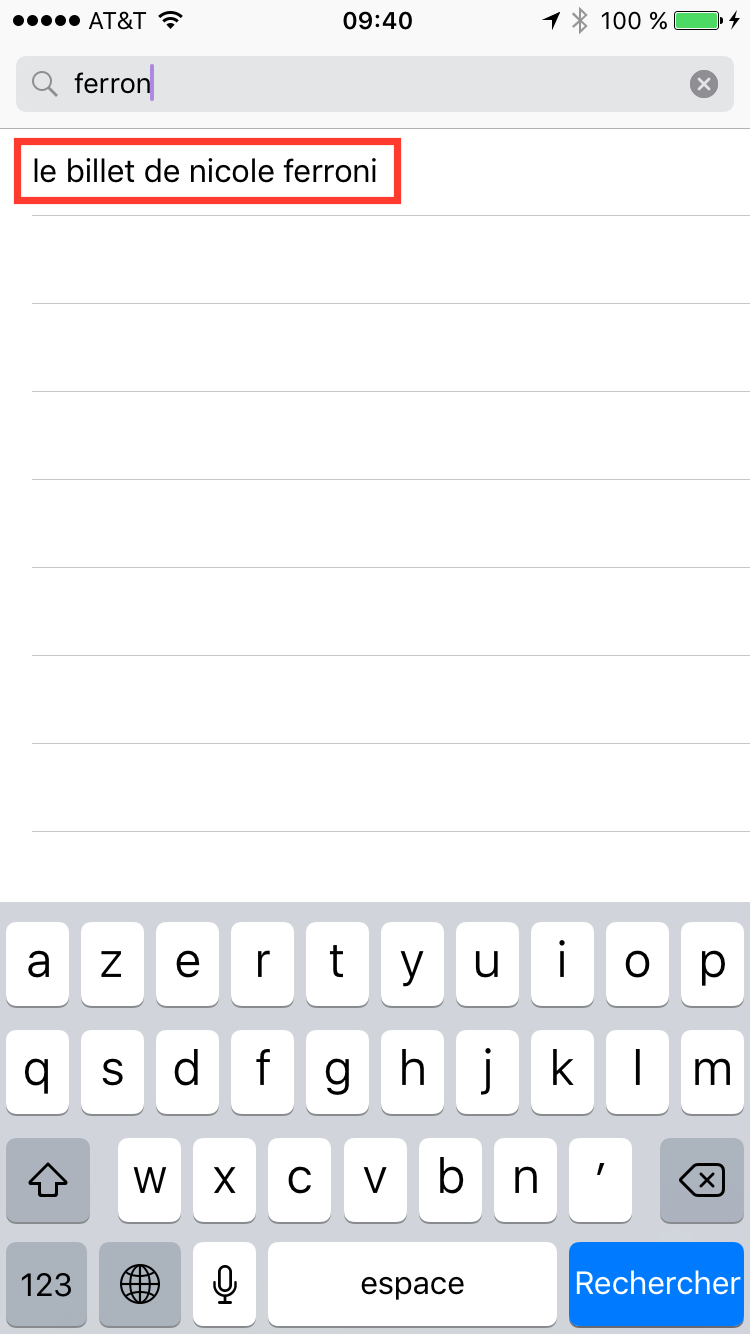
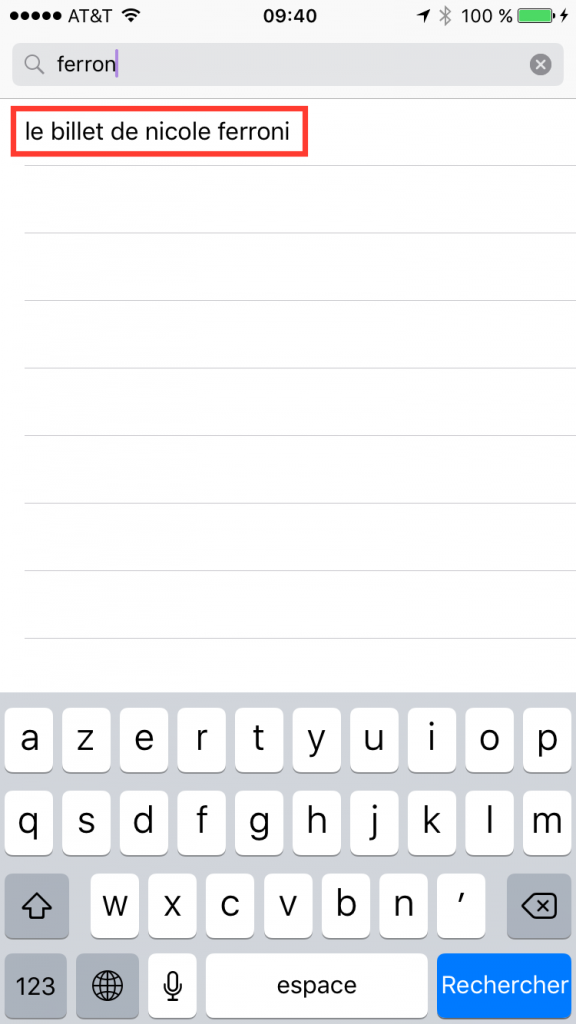
Pour la suite de l’article, nous allons choisir un podcast : le billet de Nicole Ferroni. Si il n’apparait pas dans les 3 écrans précédents, vous pouvez utiliser l’outil de recherche de l’application (choix “Rechercher” dans l’onglet du bas).
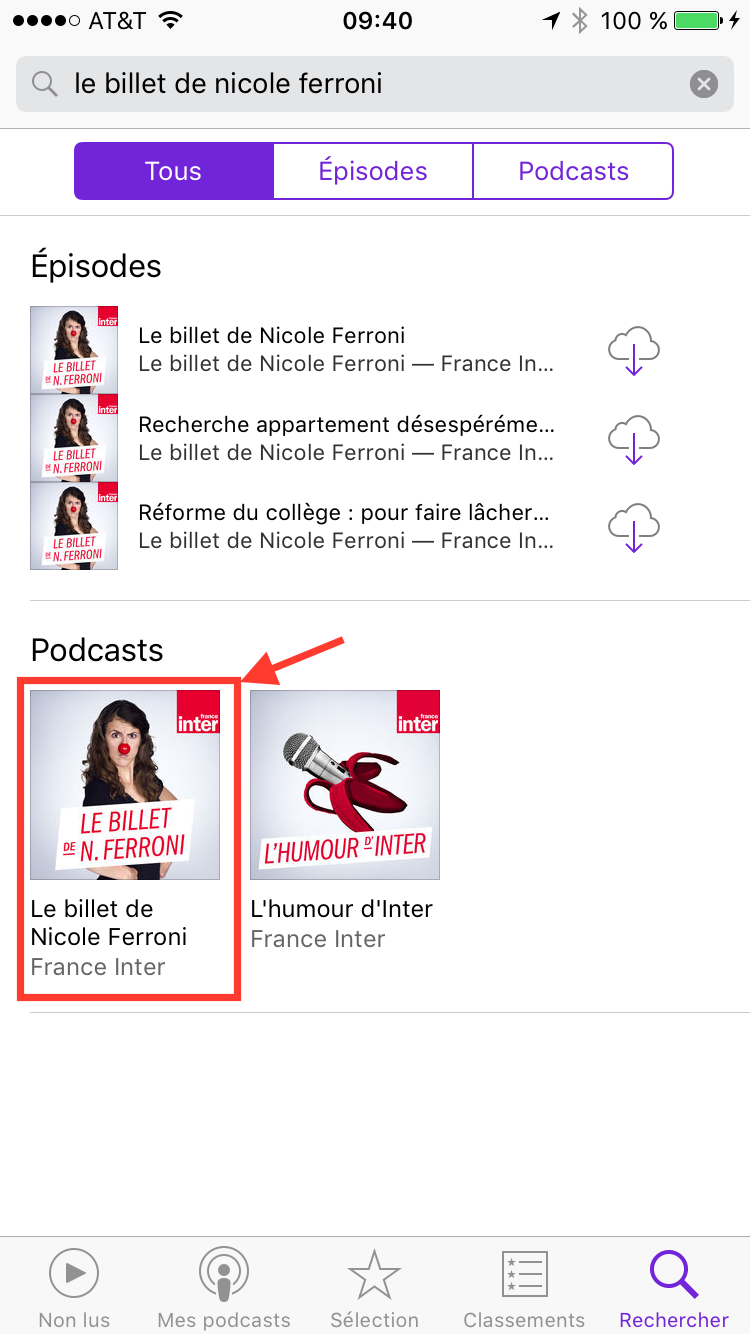
Une fois dans l’écran de recherche, tapez les premières lettre de “Ferroni” et le podcast devrait apparaitre dans la liste. Cliquez dessus :
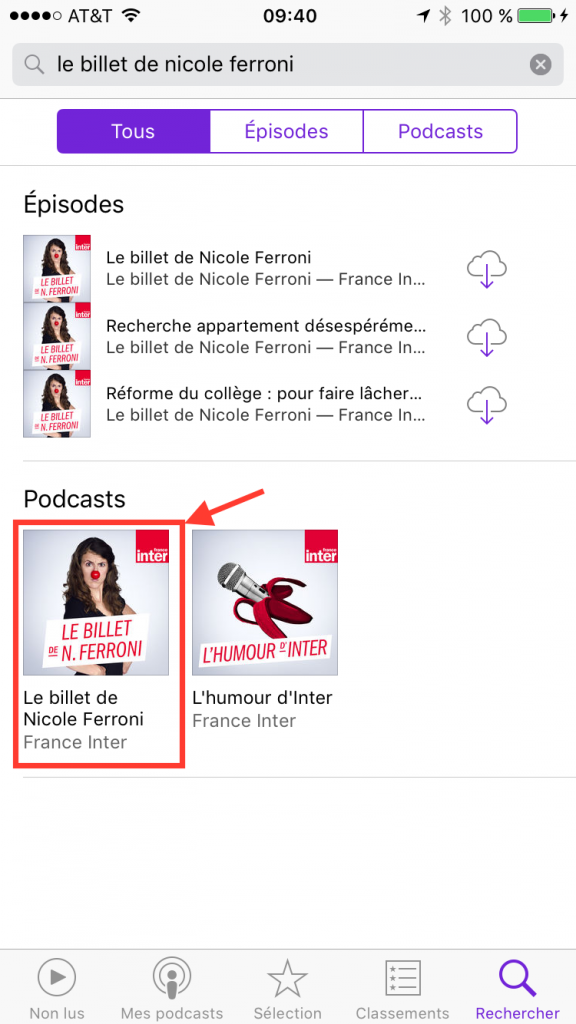
Vous arrivez dans la page de résultat de la recherche. Dans cette page il y a des épisodes et des podcasts. Plutôt que de télécharger des épisodes de façon unitaire, nous allons voir par la suite comment s’abonner à un podcast (car c’est dans ce scénario que les podcasts prennent tout le sens). Il faut donc cliquer sur le podcast “le billet de Nicole Ferroni” dans la section “Podcasts” des résultats de recherche:
4) s’abonner au podcast
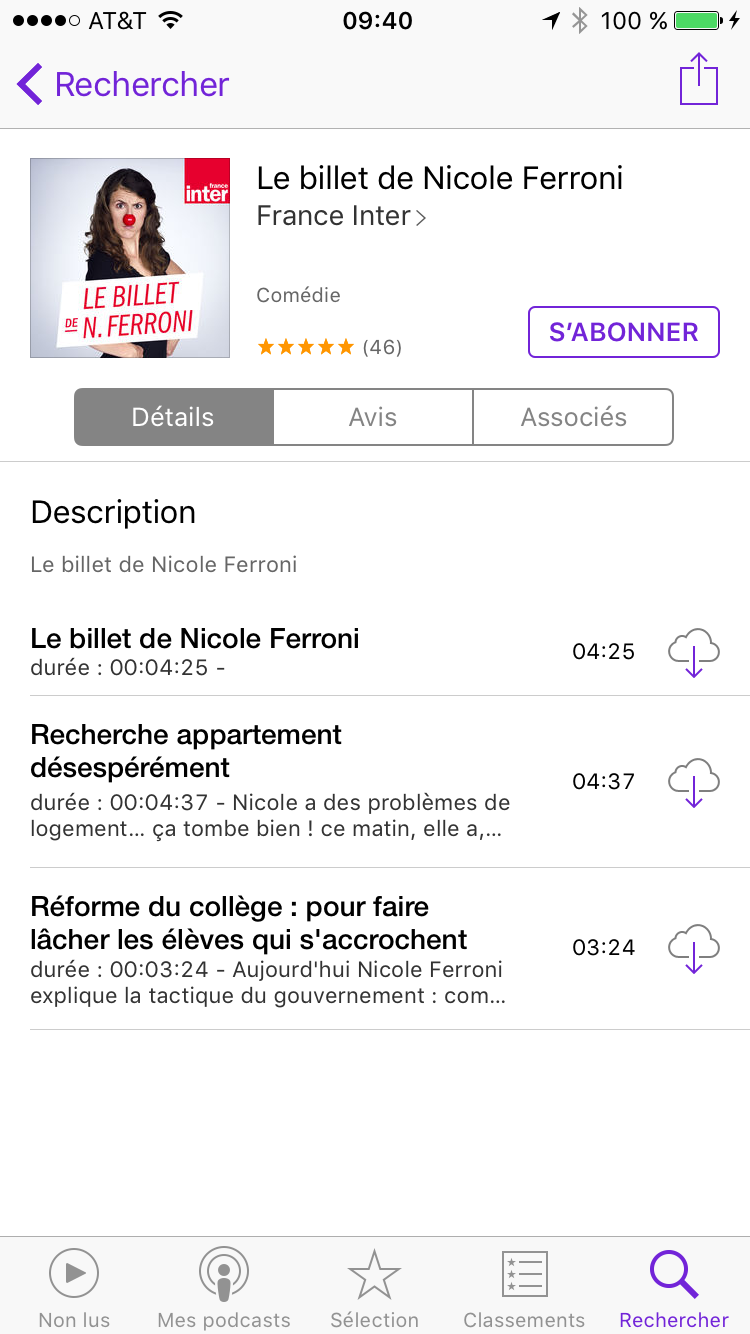
Une fois que vous êtes sur la page de votre podcast, vous avez le choix entre vous abonner au podcast (bouton “s’abonner”) ou télécharger des épisodes en particulier (les icônes ave le nuage et la flèche en face des épisodes qui sont listés):
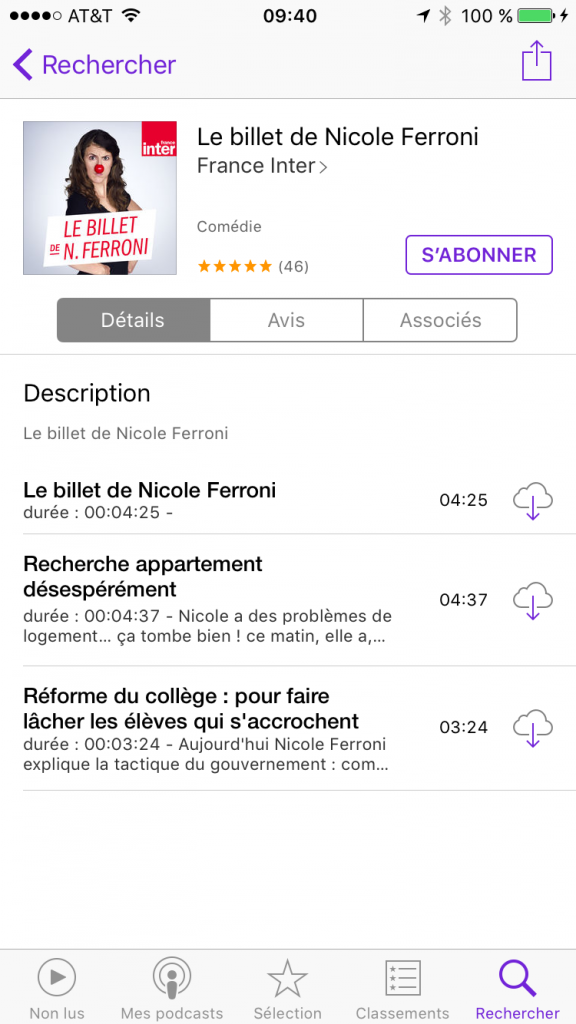
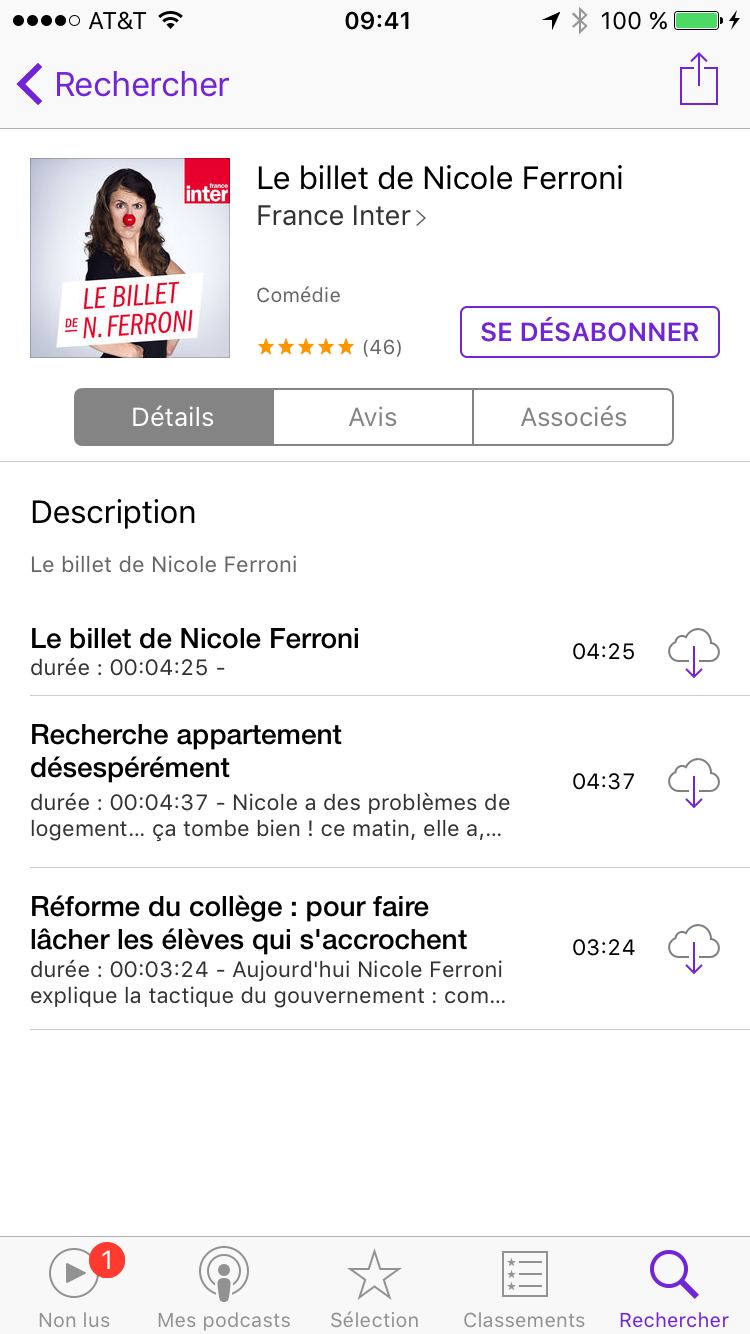
Comme expliqué plus haut, nous allons nous abonner afin de recevoir régulièrement les nouveaux épisodes futurs. Une fois que vous avez appuyé sur “s’abonner”, on voit apparaitre un petit 1 dans la barre du bas sur l’icône “non lus”. C’est là que les épisodes du podcast seront disponibles.
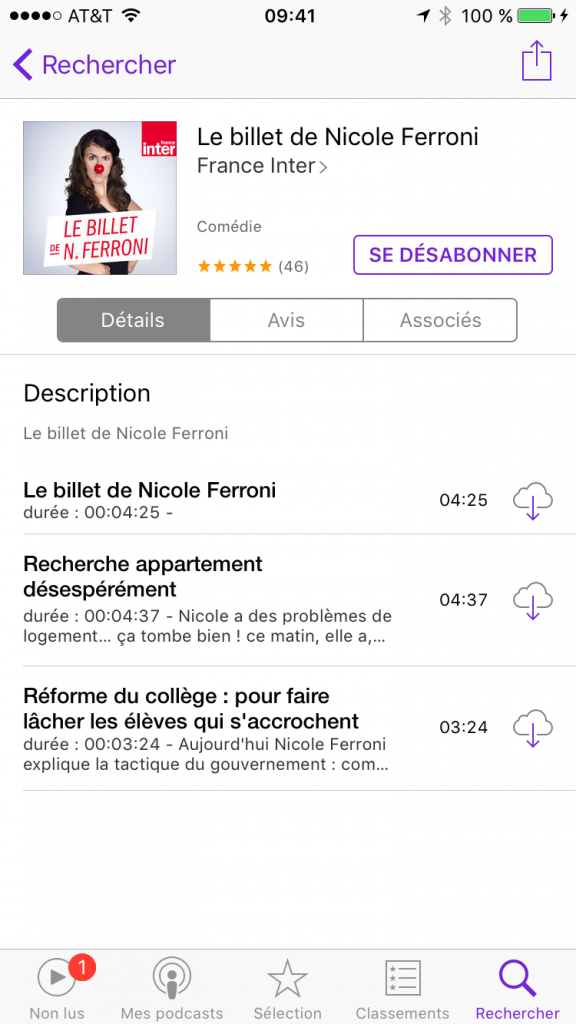
5) télécharger son premier épisode
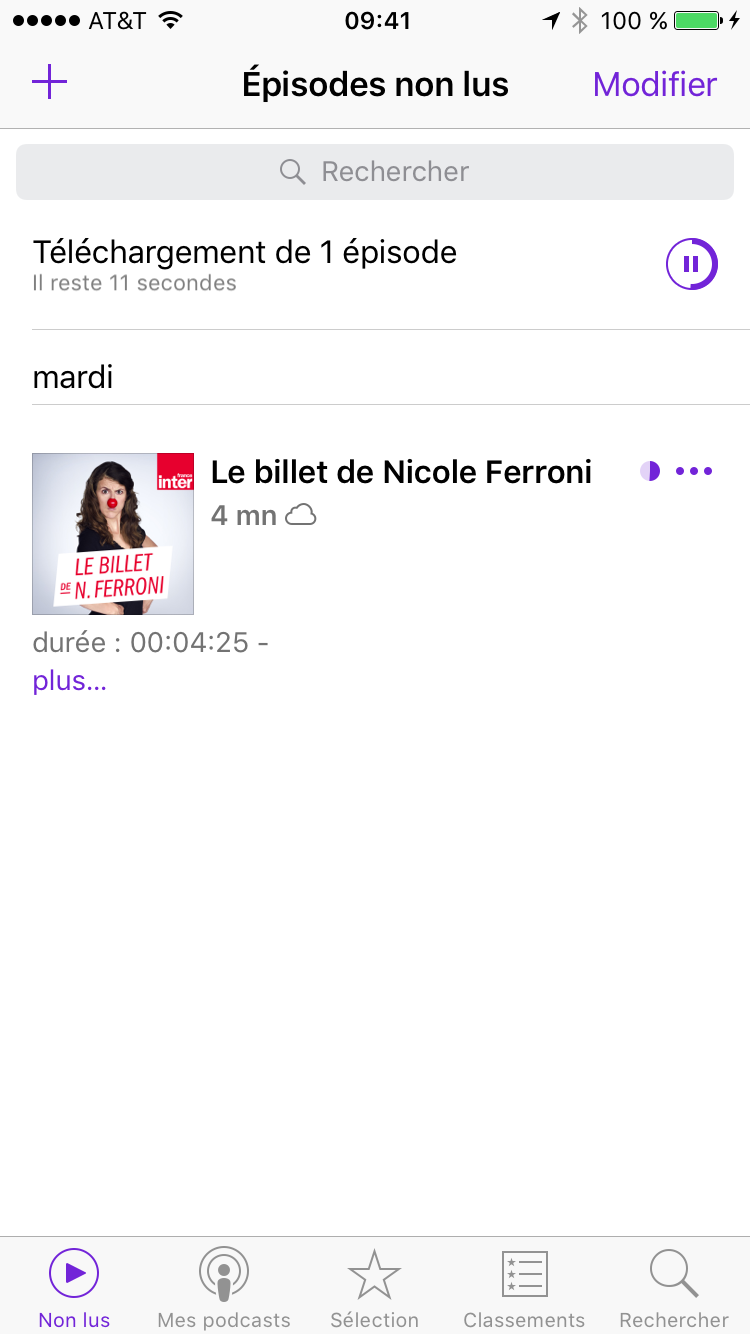
Lorsque vous vous abonnez, le dernier épisode du podcast disponible se télécharge automatiquement. Si vous allez sur l’écran “Non lus”, vous voyez que l’épisode est en cours de téléchargement:
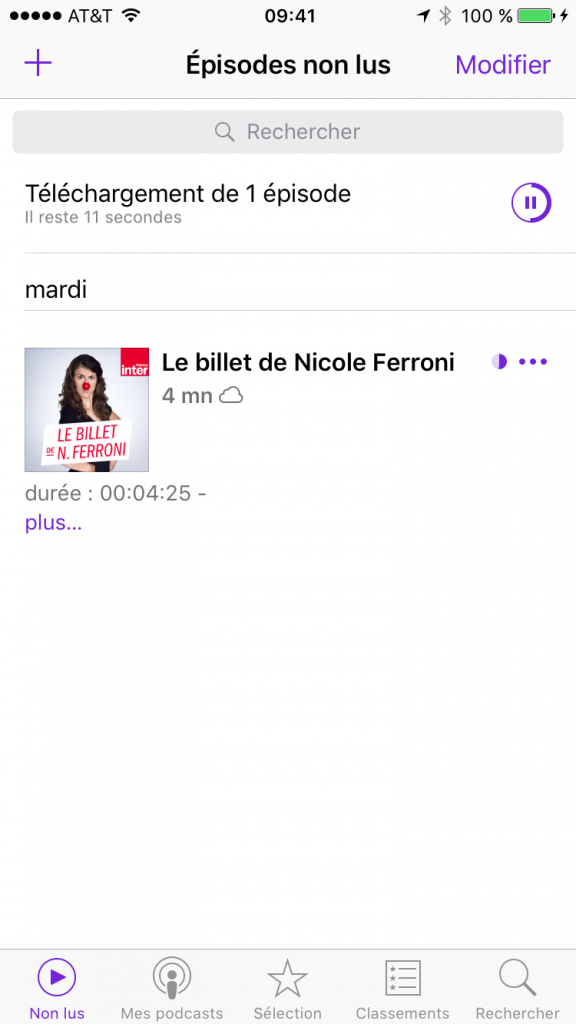
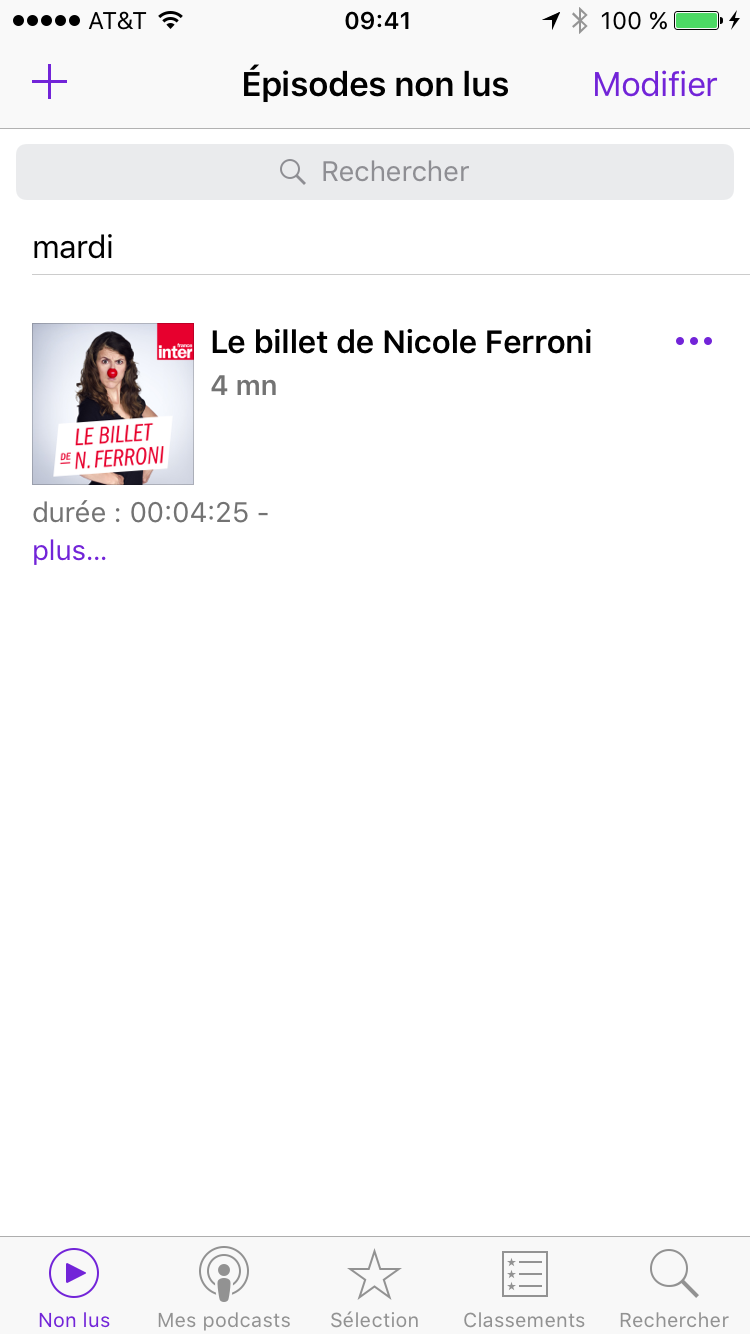
Et comme c’est un fichier audio (plutôt petit donc), le téléchargement devrait être assez rapide et il devrait être disponible pour la lecture en quelques secondes ou minutes:
6) Ecouter son premier épisode
Il suffit de sélectionner l’épisode disponible pour que la lecture commence:
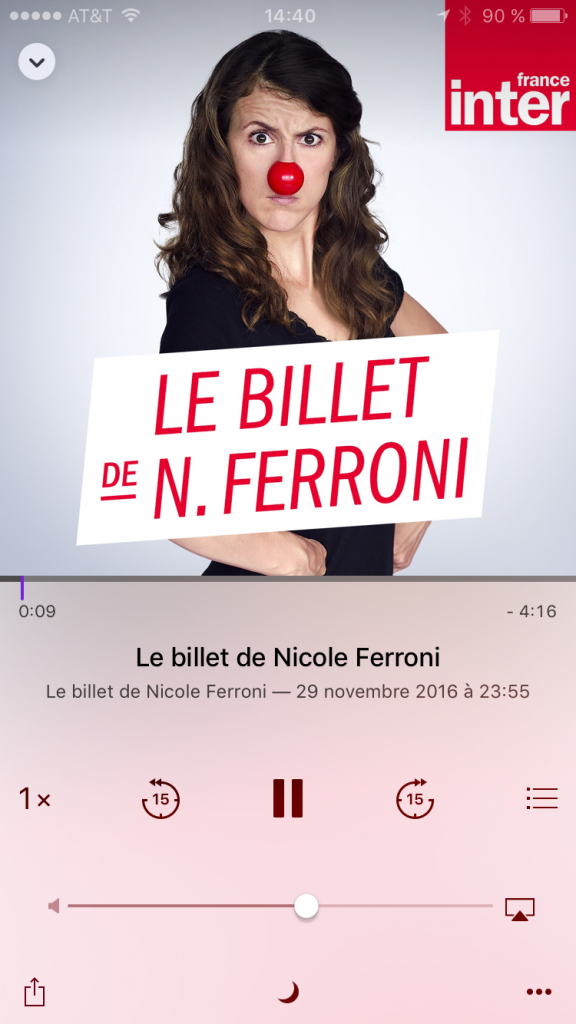 Si vous arrêter la lecture avant la fin de l’épisode, vous pourrez y revenir quand vous voudrez et cela reprendra exactement ou cela s’était arrêté.
Si vous arrêter la lecture avant la fin de l’épisode, vous pourrez y revenir quand vous voudrez et cela reprendra exactement ou cela s’était arrêté.
7) télécharger d’autres épisodes
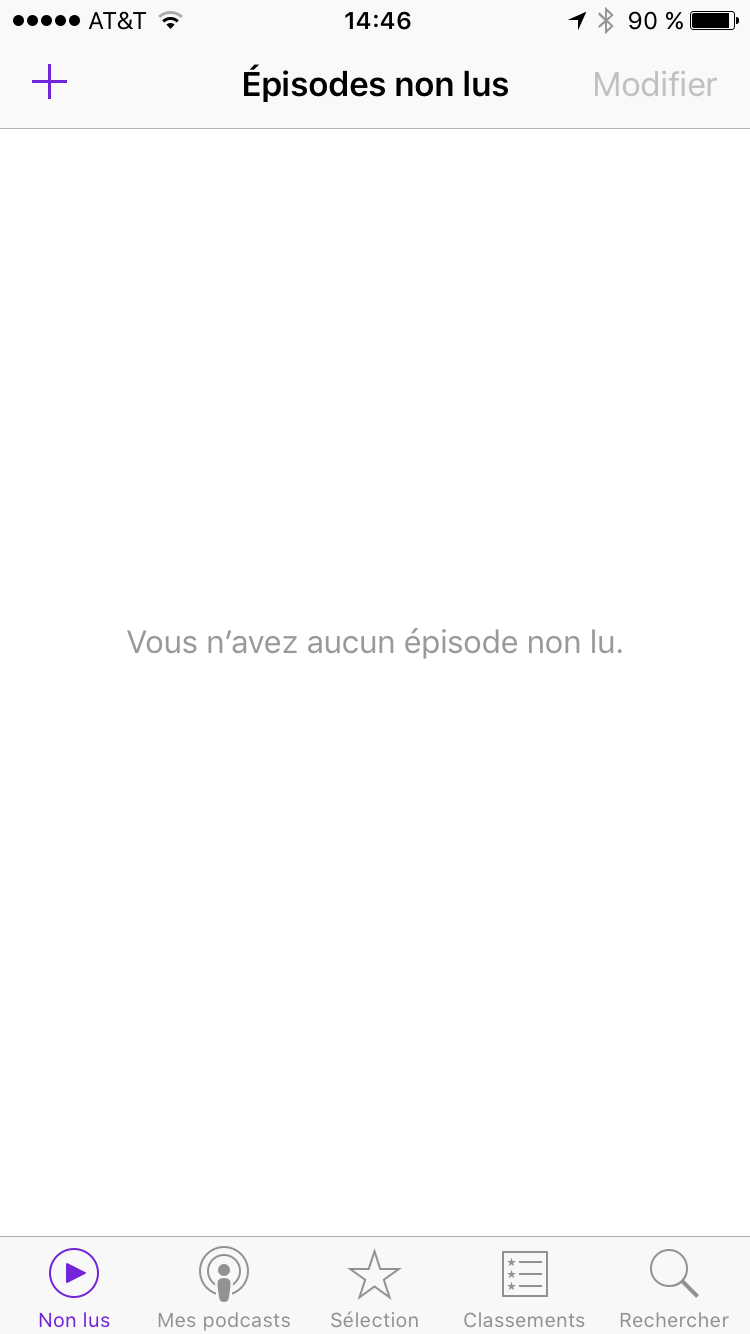
Si vous avez terminé d’écouter votre premier épisode, votre écran “Non lus” devraient maintenant être vide :
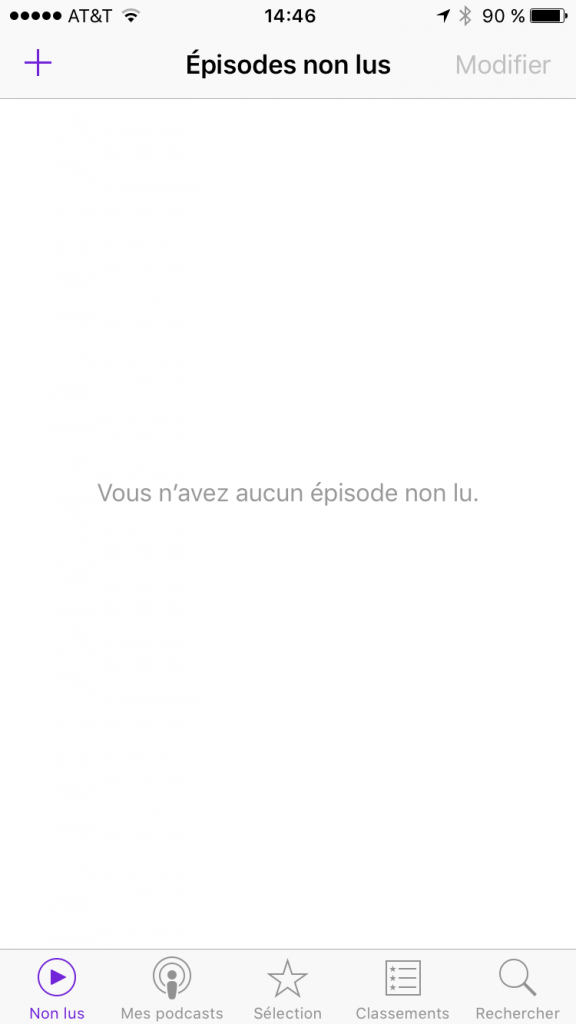
Si vous ne faites rien et attendez quelques jours, lorsque France Inter va publier un nouvel épisode de Nicole Ferroni, il sera automatiquement téléchargé (quand vous êtes sur un réseau Wi-Fi). Vote liste de lecture va donc s’alimenter toute seule en fonction des publications des podcasts auxquels vous êtes abonnés. Notez que vous ne prenez pas grand risque en terme de taille de stockage sur votre téléphone car les fichiers audios sont plutôt petits.
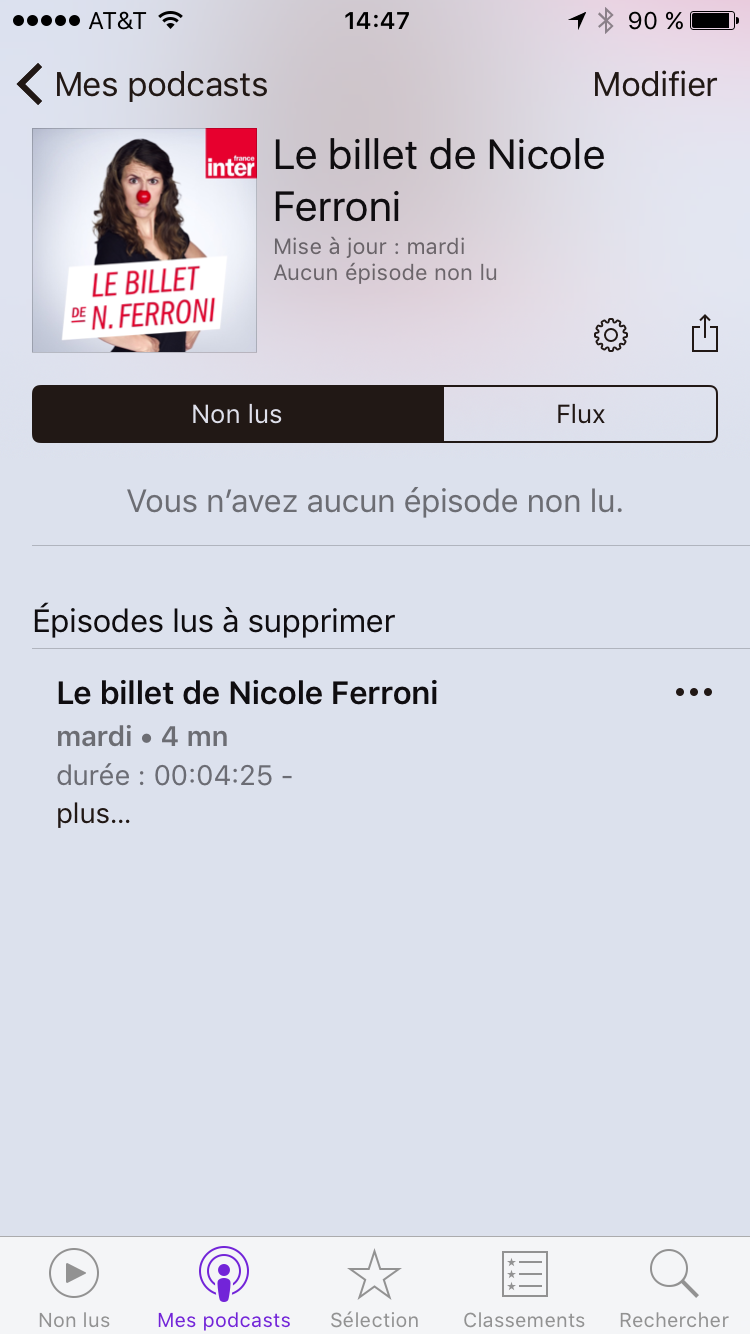
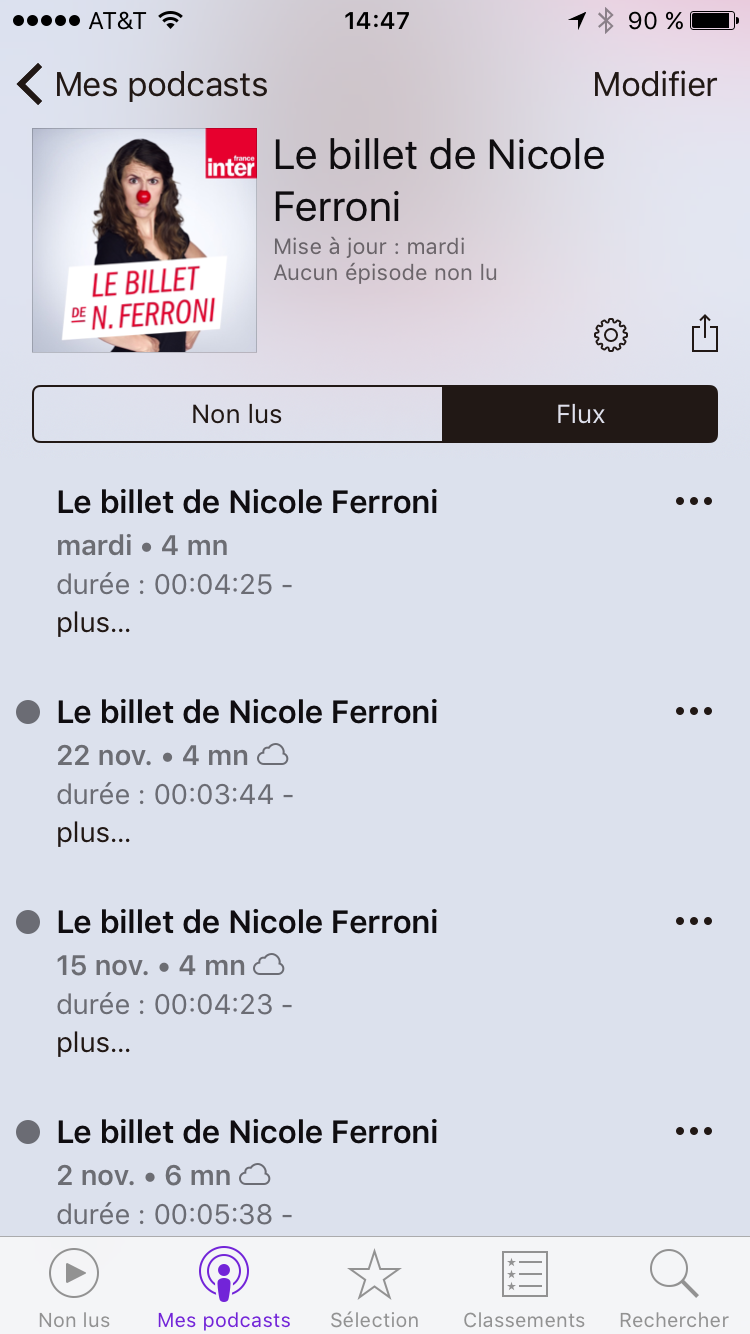
Si vous ne voulez pas attendre le prochain épisode, vous pouvez aller piocher dans les anciens épisodes. Pour cela, allez dans “Mes podcasts” et choisissez le podcast auquel vous êtes abonné:
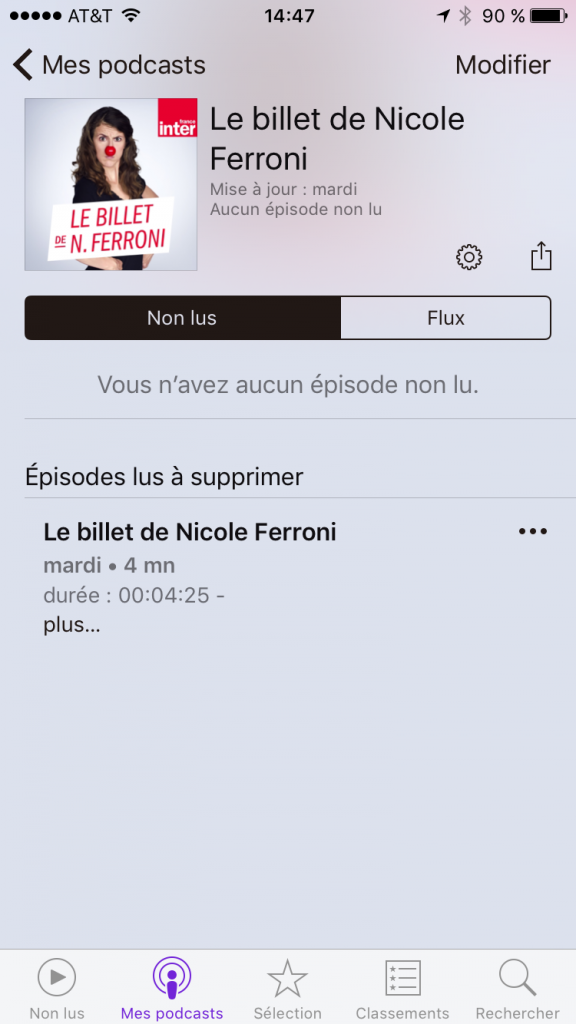
La liste des “Non lus” est vide et dessous on voit apparaitre l’épisode lu. Pour voir la liste des épisodes passés, il faut choisir l’onglet “Flux” (pas super intuitif…):
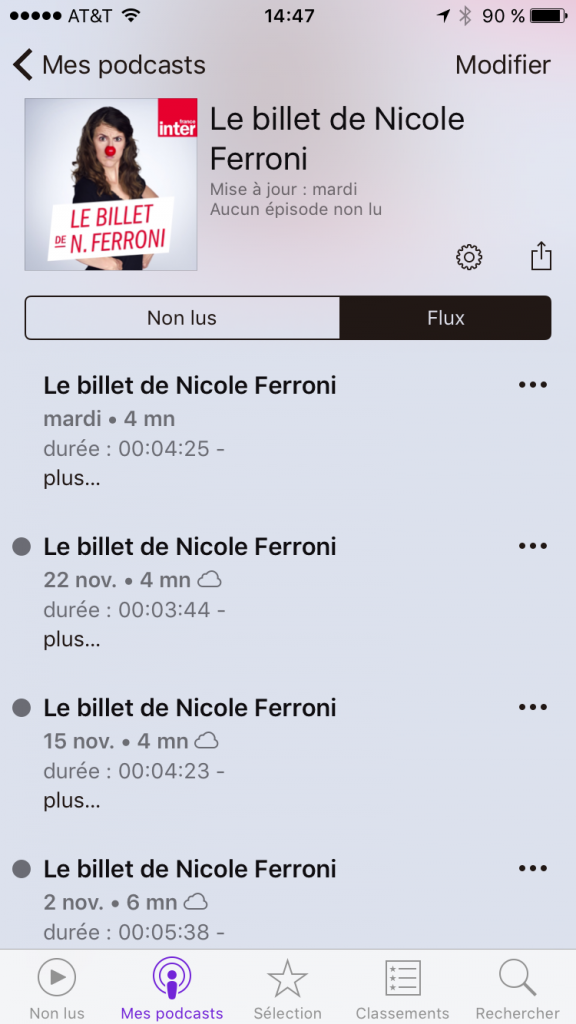
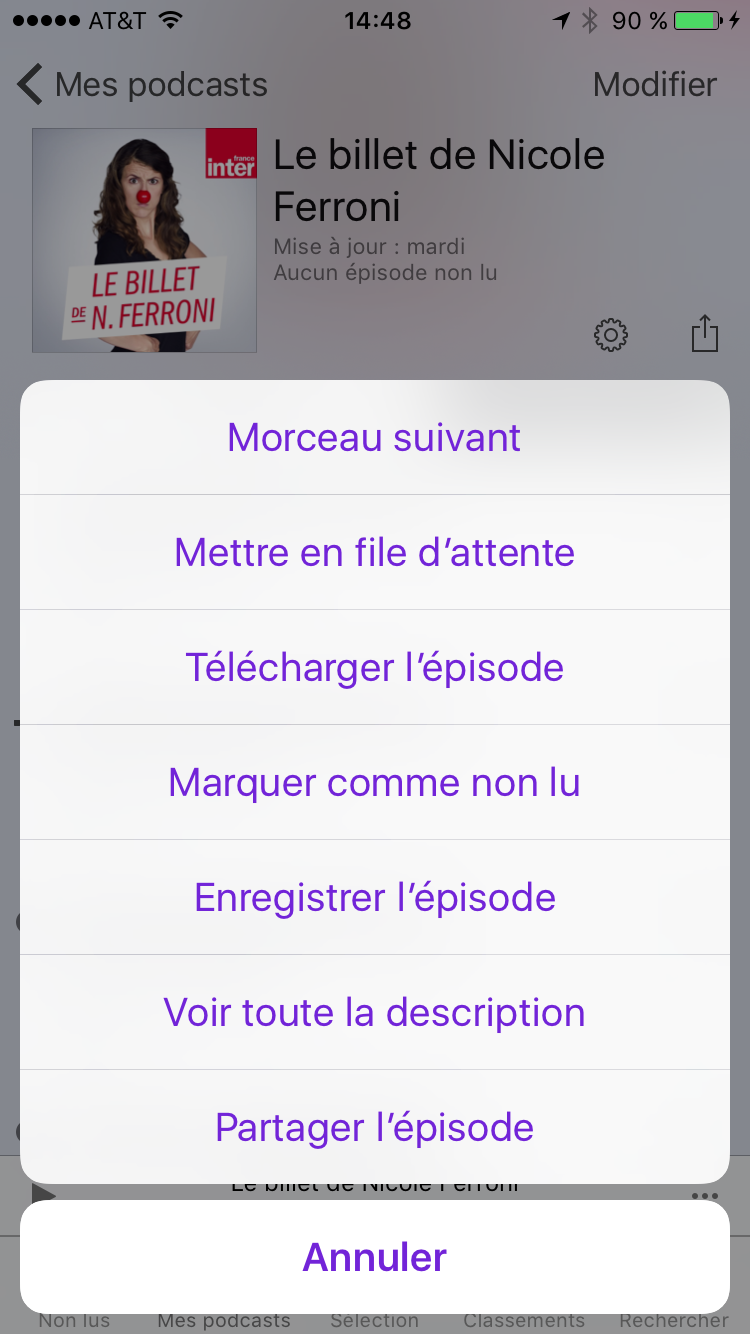
Là vous trouvez les épisodes dans l’ordre inverse de publications (des plus récents aux plus anciens). Si vous choisissez un épisode, la lecture se lance automatiquement ce qui n’est surement pas ce que vous voulez faire, l’idée étant plutôt d’en télécharger plusieurs pour les écouter en faisant son prochain footing. Pour télécharger les épisodes il faut cliquer sur les 3 petits points (encore une fois super intuitif…):
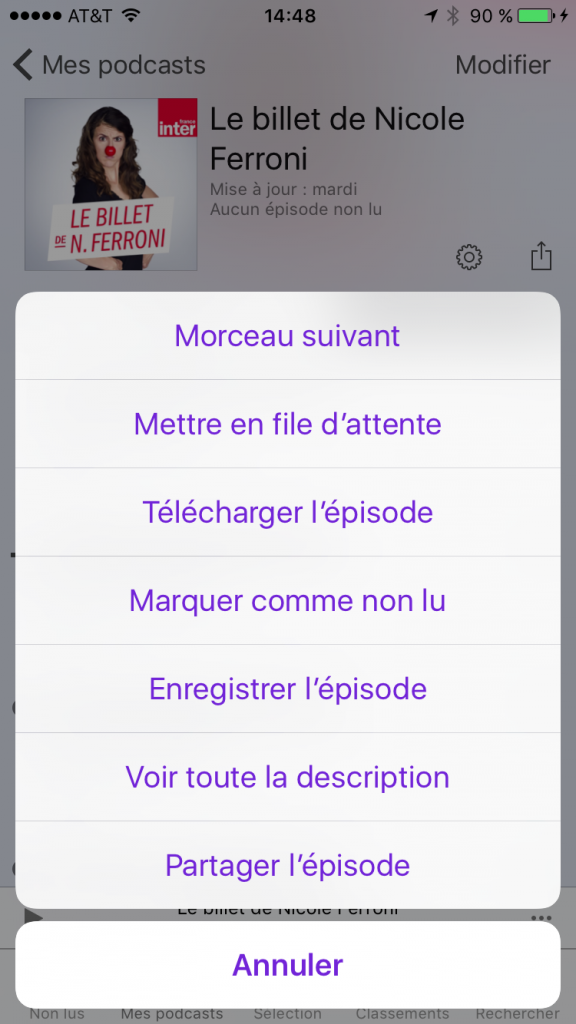
Choisissez “Télécharger l’épisode” et faites de même pour tous les autres épisodes que vous souhaitez télécharger. Ensuite vous pouvez retourner sur l’onglet “Non lus” où vous devriez retrouver les épisodes que vous avez choisis qui seront rapidement téléchargés:
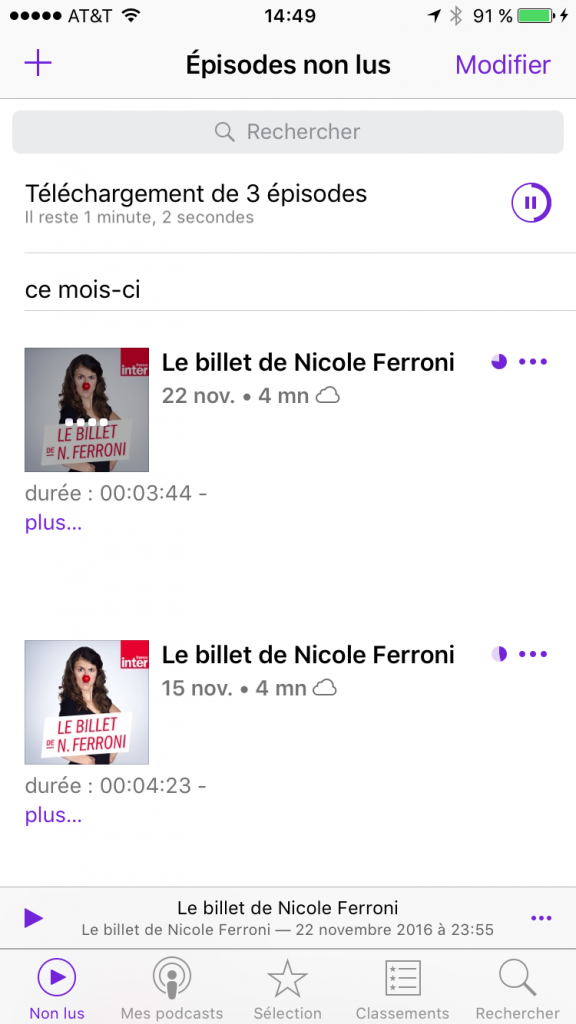
Vous savez donc maintenant faire un petit stock d’épisodes d’un seul podcast. Si vous souhaitez vous abonner à plusieurs podcasts, le principe est le même. Retournez à l’étape du choix du podcast, et choisissez d’autres podcasts auxquelles vous abonner.
Quelques informations pour aller plus loin:
- quand les épisodes s’empilent trop, vous pouvez les effacer dans l’onglet “Non lus” en balayant vers la droite (l’option “Supprimer” apparait). Même chose pour supprimer complètement un podcast: balayage droit dans l’onglet “Mes podcasts”
- si vous cherchez des podcasts à écouter, vous avez donc pas mal de choix dans l’application, mais vous pouvez toujours jeter un coup d’oeil à ma selection.
- si l’application “podcast” vous donne des boutons, vous pouvez aller regarder du côté de Overcast qui est très bien faite (mais pas non plus complètement intuitive)
Bonne écoute !!!