Robot Framework and pytest are two popular test automation frameworks used in the Python community. At first glance, their usage seems to be different. Robot Framework is advertised as a “generic test automation framework for acceptance testing” and the first example of the home page is a login/password test written in a DSL that puts it in the black-box testing category. Whereas pytest home page shows a unit test of a Python method hence more white-box testing oriented.
So is the situation clear? On one side Robot for not-so-technical QA doing automation on the final product and on the other side pyTest for developers writing unit tests? Not so sure as pytest can be used for high-level functional test automation as well (“complex functional testing for applications” stated in pytest home page). So how do both framework compare for functional tests automation?
Let’s start by writing a minimal test in both frameworks. For our simple example, the SUT will be git and we will check the output of git version command called from the command line.
The test in pytest:
import subprocess
def test_command_line():
p = subprocess.Popen('git --version', shell=True, stdout=subprocess.PIPE)
p.wait()
assert p.stdout.read() == 'git version 2.15.2 (Apple Git-101.1)\n'
And its execution:
pytest test_with_pytest.py
======================================== test session starts ========================================
platform darwin -- Python 2.7.15, pytest-3.7.2, py-1.5.4, pluggy-0.7.1
rootdir: /Users/laurent/Development/tmp/pytest, inifile:
collected 1 item
test_with_pytest.py . [100%]
===================================== 1 passed in 0.02 seconds ======================================
The test in Robot Framework:
*** Settings ***
Library Process
*** Test Cases ***
test_command_line
${result} = Run Process git --version
Should Be Equal ${result.stdout} git version 2.15.2 (Apple Git-101.1)
And its execution:
pybot test_with_robot.robot
==============================================================================
Test With Robot
==============================================================================
test_command_line | PASS |
------------------------------------------------------------------------------
Test With Robot | PASS |
1 critical test, 1 passed, 0 failed
1 test total, 1 passed, 0 failed
==============================================================================
Output: /Users/laurent/Development/tmp/pytest/output.xml
Log: /Users/laurent/Development/tmp/pytest/log.html
Report: /Users/laurent/Development/tmp/pytest/report.html
On this specific example, the test syntax is quite similar. There is not so much boilerplate code for pytest so the advantage of Robot’s DSL is not so obvious. A first difference
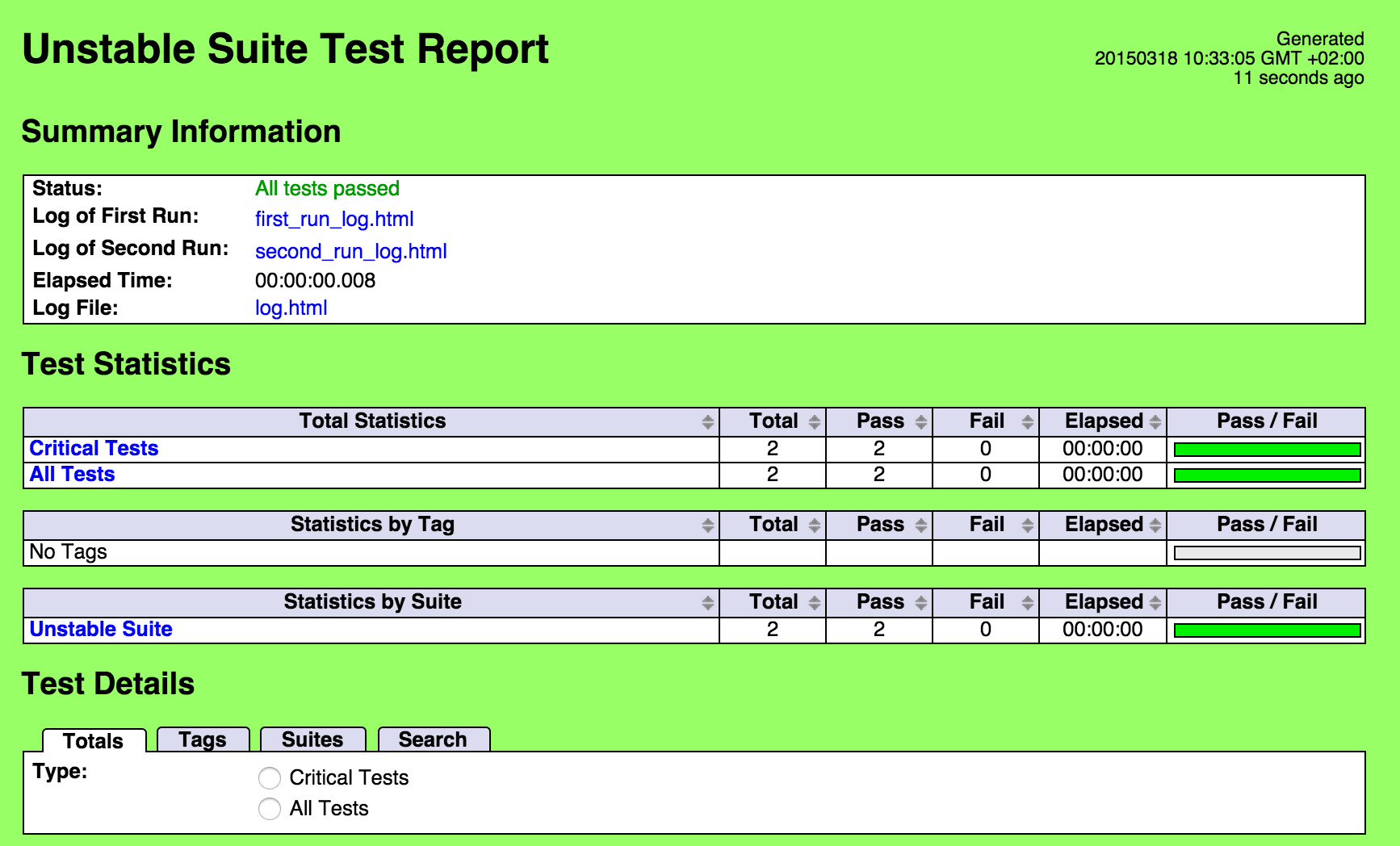
we can note is that is for the report/log: by default pytest does not provide any HTML report/log file whereas Robot does. To get HTML report for pytest one need to install pytest-htm and invoke pytets with argument --html=report.html
Here is a quick comparison of other useful features:
| Feature | pytest | Robot Framework |
|---|---|---|
| Setup/Teardown | xunit setup | setup and teardown |
| Tagging/Marking tests | markers | tags |
| Management of expected failures | xunit skipping tests | non critical tests |
| Get some print/debug messages on stdout while tests are running | pass -s option to pytest command | Log to console |
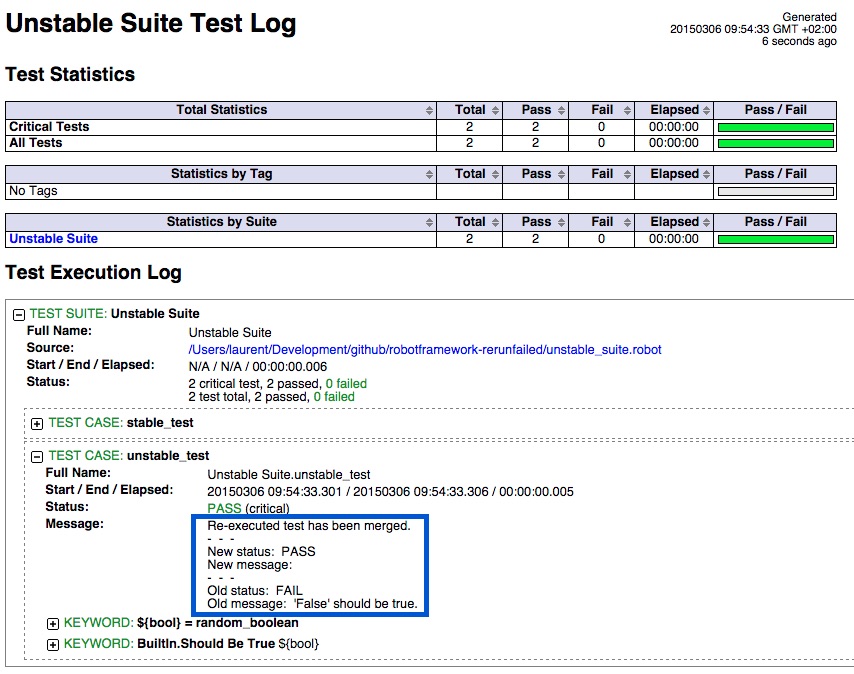
| Rerun failed test | rerunning-only-failures-or-failures-first | re-executing-failed-test-cases |
| running tests in parallel | xdist and pytest-parallel | pabot |
| Stopping after the first (or N) failures | stopping-after-the-first-or-n-failures | not available |
On a more general note, Robot should be easier to start with for people with lower development skills as it is using a simple test-oriented DSL with rich built-in libraries. But to build more complex/complete automation, users will have to switch do Python code anyway at some point. On the other end, pytest requires to start with a full-fledged langage but this comes with many features as well (huge IDE support, static code analysis etc.). So all in all, it seems that both frameworks can be used for functional test automation with no obvious winner.
For another comparison of the two frameworks, see the blog post “The classic dilemma for testers – Robot or pytest” from Opcito.
And if you have any input on this topic, feel free to leave a comment!